Amazon S3 is by default choice for data lake. There are 3 primary considerations when dealing with Analytics suite of services.
- What are the data sources and which services to be used for data movement?
- What kind of transformation requirements we have? Light vs Heavy transformations?
- What would be our data sink (to park transformed data) to plug our visualization tools/ML algorithms?
What is a data lake in AWS?
AWS Simple Storage Service (S3) serves as a data lake platform. It is just an object space which is fully manged by AWS. So, you don’t need to worry about scaling of your data into your data lake. All kinds of data, i.e., batch (your logs, databases, API calls), streaming data can very easily land in the Data Lake. This is the platform to store your ingested data from various sources so you can further decide what do with data – as per your use case.
AWS S3 glacier is used for data which is not in instant use. You may like to archive it and save some cost. There are retrieval mechanism and time limits, which you definitely like to go through before archiving data.
There are multiple services that offers data movement into data lake and few of them are mentioned below.
AWS S3 is considered a very cheap storage. For pricing considerations, you may like to refer: https://aws.amazon.com/s3/pricing/
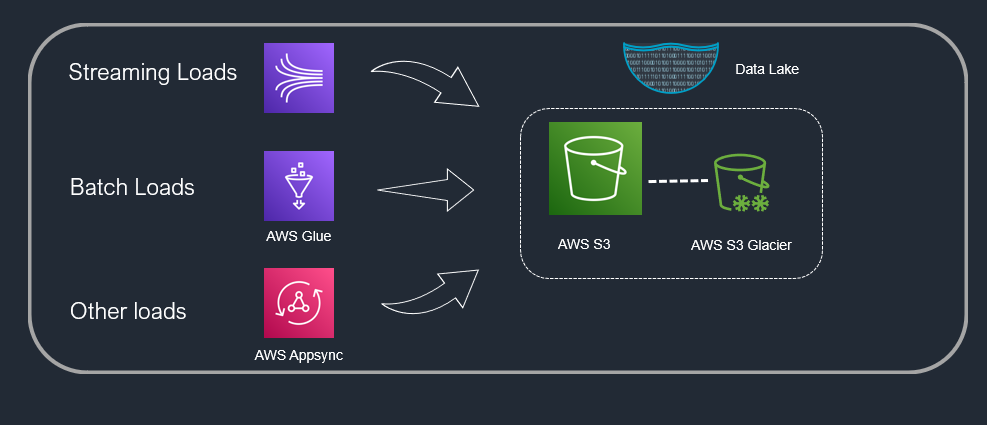
What next?
You have got the data in your data lake. Now it’s time to evaluate your business use case to effectively select the AWS data analytics services.
Use Case 1: Simple SQL Analytics
You want to create a data lake that will have different files (logs, SQL and No SQL database’s data, API data) across data sources and you wish to run SQL queries against this data. This could be an initial POC for someone exploring AWS analytics suite.
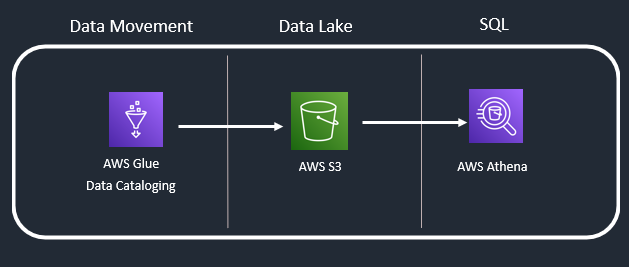
AWS Glue: This primarily performs 2 actions. Create a Catalog (metadata for your input source) and secondly move data from source to AWS S3 data lake.
AWS S3: AWS Data Lake object storage. There are also many options available for different storage tiers to save on cost.
AWS Athena: Athena provides a simplified, flexible way to analyse petabytes of data where it lives (Amazon Simple Storage Service (S3) data lake). Makes use of data Catalog created by AWS Glue.
Use Case 2: SQL Analytics + Visualization
In this use case you want to include visualization capability to your SQL analytics. You may consider “AWS Quick sight “(for seamless integration). You can also select any other popular data visualization tool like Tableau, Power BI etc.
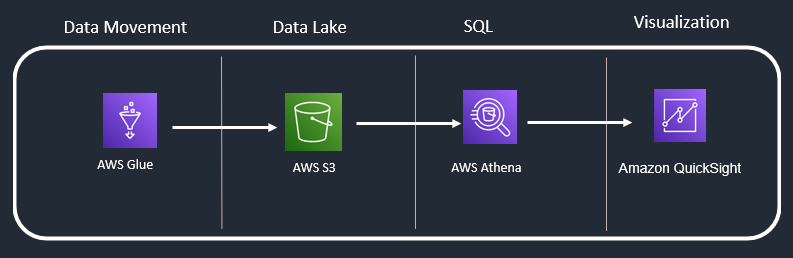
AWS Athena: You must enable Quick Sight to access Amazon Athena and S3. If Quick Sight does not have these rights, it won’t be able to analyse and visualize the data we have queried in Athena.
AWS Quick sight: AWS managed service, offers industry standard crisp visuals for interactive dashboards and KPIs.
Use Case 3: SQL Analytics + Light Transformations + Visualization
In the ideal world, you never get the data you intend to in your data lake. You are lucky if you discovered minor changes needs to be done. Thanks to “AWS Glue” for its many in built transformations which helps engineers to transform data. You like to transform data before loading into Data Lake (ETL) or want to transform after moving to data lake (ETL) depends on your business case.
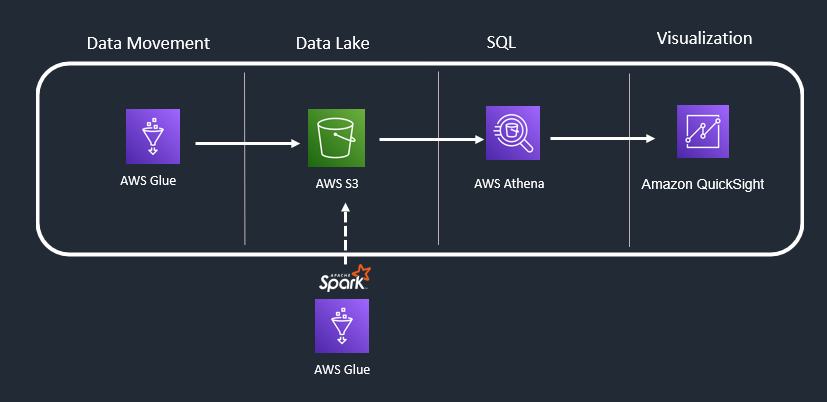
AWS Glue supports Scala and python language to leverage Apache Spark capabilities. It provides access to your transformation code, which you can also modify to achieve little more complex transformation.
Use Case 4: SQL Analytics + Heavy Transformations + Visualization
Well, you have not been lucky to figure out easy transformations with AWS Glue to achieve desired outcomes. Also, there is a need to perform multiple transformations on massive data across your data lake files/objects – No worries you can explore” AWS EMR”.
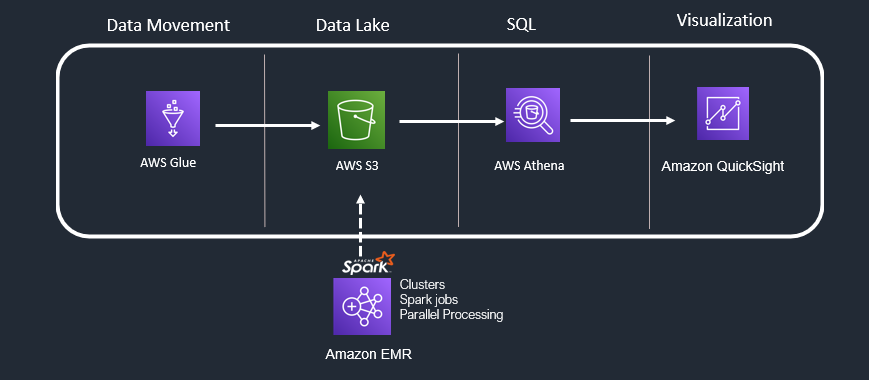
AWS EMR :Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine learning using open-source frameworks such as Apache Spark, Apache Hive, and Presto.
Use Case 5: SQL Analytics + Heavy Transformations + Dedicated Data Warehouse
Your organization wants a dedicated data warehouse because Athena queries are not fulfilling the performance aspects. You need a dedicated data warehouse that can be used by analysts to make use of MPP (Massive parallel processing) for highly optimized and fast processing of your query results. You may also like to have enhanced security in your dedicated warehouse and wants to achieve ACID transactions. Consider “Amazon Redshift”.
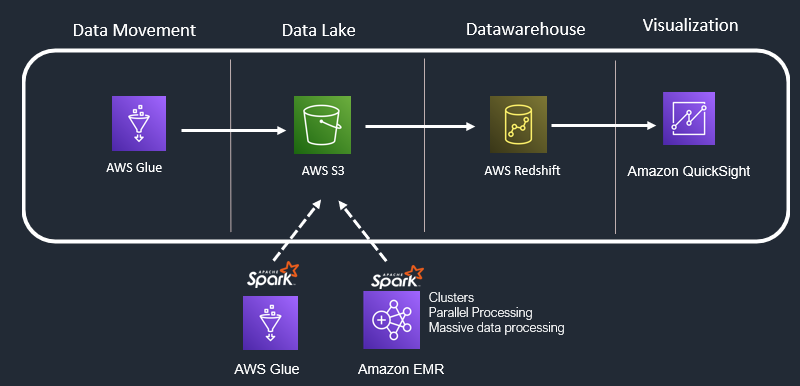
AWS Redshift: Amazon Redshift uses SQL to analyse structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and machine learning to deliver the best price performance at any scale.
Well, you also like to save some costs, if possible, because eventually you have a large old data that is still in Amazon S3 or Amazon RDS, required rarely in query joins in Redshift and you are still moving whole data to Redshift – somewhat waste of resources.
Consider “Redshift Spectrum” with S3.
Consider “Redshift federated query” with Amazon RDS.
Use Case 6: Streaming Data + SQL Analytics + Heavy Transformations
Streaming data is a continuous stream of small records or events (a record or event is typically a few kilobytes) generated by thousands of machines, devices, websites, and applications
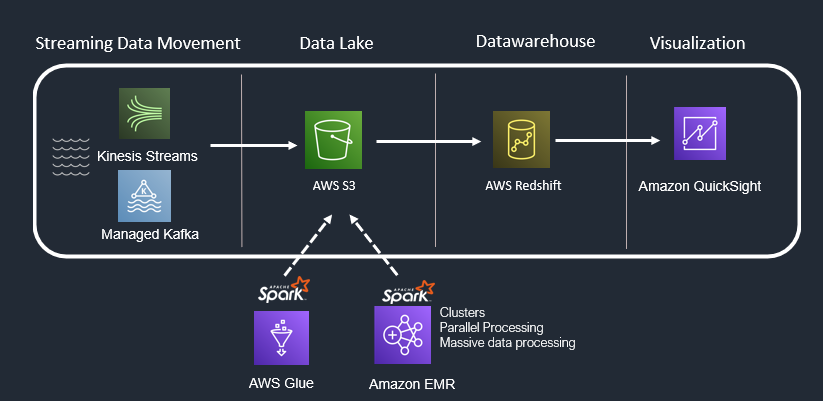
When you have streaming workload, consider “Amazon Kinesis” suite or “Amazon managed Kafka (MSK)” to read from source.
Amazon Kinesis: Amazon Kinesis is a managed, scalable, cloud-based service that allows real-time processing of streaming large amount of data per second.
Amazon Managed Streaming for Kafka (MSK): Amazon Managed Streaming for Apache Kafka (Amazon MSK) is an AWS streaming data service that manages Apache Kafka infrastructure and operations.
Use Case 7: Batch Data + Heavy Transformations + ML Workloads
When you have machine learning requirements Consider “Amazon SageMaker”. It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis. It also provides common machine learning algorithms that are optimized to run efficiently against extremely large data in a distributed environment. When your machine learning model is ready, you need a model serving endpoint for external world applications to interact with your model.
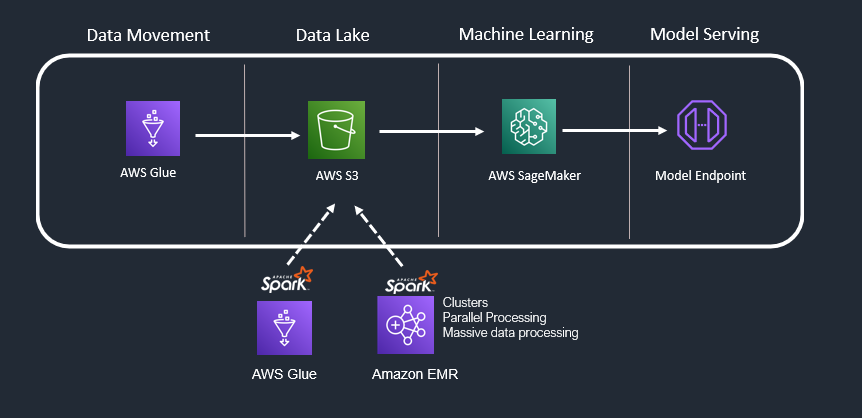
Amazon Sage Maker: It is a fully managed machine learning service. With SageMaker, data scientists and developers can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment.
Conclusion
Amazon Offers a wide variety of data analytics services that has very tight integration. It may be overwhelming initially, but as soon as you understand the scenario where a service is preferred and what problem it solves, it will help you to design your architecture quite comfortably. There are other supporting services like triggers based on AWS lambda and data movement orchestration using Data Pipelines or AWS Step functions which comes handy while designing the complete ecosystem on AWS data analytics.
Usually, the use case determines which services can be the best choice for your analytics architecture. AWS Pricing calculator will help to determine the costs upfront. Also keeping your AWS services in same region helps to save on cost as data won’t be transferred outside a region.
By having a good understanding of AWS core services covered in this article you are now empowered to design cost efficient, scalable and highly efficient architectures for your Data analytics use cases.
AWS Data Analytics - Service Selection